On Atomic Norms May 25, 2013
How many linear measurements do you need to (efficiently) recover a low rank matrix? What about a sparse vector or an orthogonal matrix? Given that we know our object of interest has some ‘structure’, can we answer this question in a general manner?
In this article, I will show you one approach to do so; regression using atomic norms. Most of the material I will cover was presented in the paper, “The Convex Geometry of Linear Inverse Problems” by Venkat Chandrasekaran, et. al.
I will begin by describing the problem of structured recovery with a few motivating examples. I will then review some facts about convex geometry and what atomic norms are in this context. Next, I will show how these properties translate to sharp recovery guarantees, instantiating the framework with two examples; the recovery of low-rank matrices and orthogonal matrices.
There are several more examples described in the paper that I will not talk about. Notably, I will not cover the details about theta bodies, approximations that the authors present, which trade off sample complexity for computational efficiency.
Note. Unfortunately, I have not been able to manipulate Pandoc and MathJax to do equation and theorem referencing. A PDF version of this article can be found here.
Edit (27th May, 2013): I had used \(\cup\) in several places where I had really meant \(\cap\).
Motivation: Recovering under-determined objects using structure
The problem of recovering sparse but high-dimensional vectors from data (“compressed sensing”) has seen recent success in applications to genotyping, medical imaging and comes up commonly when dealing with sensor data. Similarly, the recovery of low-rank matrices and tensors has been used to analyze fMRI data. It also comes up in the recovery of signal from only the magnitude measurements (i.e. without phase), using the PhaseLift algorithm.
The Mixture of Linear Regressions
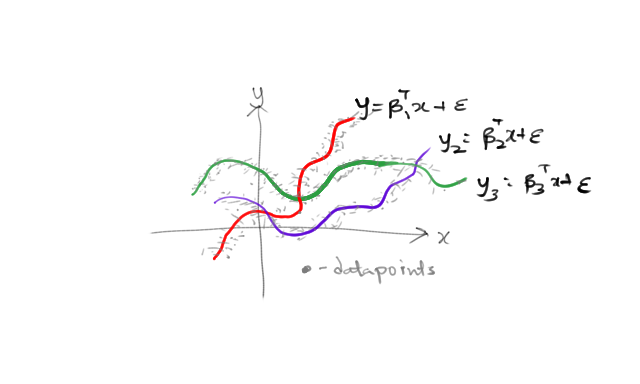
Personally, I came to be interested in this formulation from my work on applying the method of moments to the mixture of linear regressions, with Percy Liang. In that algorithm, we provided a consistent estimator for the discriminative model where we observe data \((y_i, x_i)\), where \(y_i = \beta_h^T x_i + \epsilon_i\) and \(\beta_h\) is one of \(\beta_1, \beta_2, \dots \beta_k\); we do not observe which and do not know what the \(\beta_h\) are. Of course, \(x_i\) could actually be features so the data could describe curves instead of lines, as depicted in the picture above.
The problem is to learn the \(\{\beta_h\}_{h=1}^k\), and we do so by observing that \(y_i^2\) are linear measurements of \(\mathbb{E}_h[\beta_h^{\otimes 2}]\), etc. After recovering these moments, we apply standard techniques to recover \(\{\beta_h\}\). In these regression problems, we exploited the low-rank structure to recover the moments with just \(O(kd)\) samples instead of potentially \(O(d^3)\) samples!
The results of this paper allow us, conceptually at least, to extend this approach to efficiently recover the moments from some linear measurements.
The Structured Recovery Problem
I will now talk about the exact problem we are looking at. This needs some definitions.
Suppose that the object (matrix, tensor, etc.) we wish to recover is the convex combination of a few “atoms” in the atomic set \(\mathcal{A}\), \[ \begin{align*} x^* &= \sum_{i=1}^k c_i a_i, & a_i \in \mathcal{A}, c_i > 0. \end{align*} \]
We can define the atomic norm of this set to be, \[ \begin{align*} \|x\|_{\mathcal{A}} &= \inf \{ t: x \in t \textrm{conv}{\mathcal{A}} \}. \end{align*} \] Intuitively, this function tells us how much we need to scale \(\mathcal{A}\) so that it’s convex hull contains \(x\). In principle, \(\|\cdot\|_{\mathcal{A}}\) is only a norm when \(\mathcal{A}\) is “centrally symmetric” (\(a \in \mathcal{A}\iff -a \in \mathcal{A}\)). The results in the paper extend to non-centrally symmetric \(\mathcal{A}\) as well, so we will just assume that \(\|\cdot\|_{\mathcal{A}}\) is a valid norm here.
Examples. Two standard choices for \(\mathcal{A}\) are the set of 1-sparse vectors (for sparse recovery) and set of rank-one matrices (for low rank recovery). The corresponding norms are, as expected, the \(L_1\), \(\|\cdot\|_{1}\), norm and the nuclear norm, \(\|\cdot\|_{*}\).
Let \(\Phi\) be a linear measurement operator. We wish to ask, how many linear measurements \(y = \Phi x^*\) are required to exactly recover \(x^*\) from the convex program, \[ \begin{align} \hat x &= \arg\min_{x} \| x \|_{\mathcal{A}} \label{opt-exact} \\ \textrm{subject to}~ & y = \Phi x. \nonumber \end{align} \]
The approach also handles the case where the observations are noisy, \(y = \Phi x^* + \omega\), where \(||\omega||_2 \le \delta\); \[ \begin{align} \hat x &= \arg\min_{x} \| x \|_{\mathcal{A}} \label{opt-noisy} \\ \textrm{subject to}~ & \|y - \Phi x\|_2 \le \delta. \nonumber \end{align} \] In this case, we will ask instead for the number samples required so that \(||\hat x - x^*|| \le \epsilon\) for any \(\epsilon\).
Convex Geometry Prelimnaries
Before we proceed, I will need to review a few simple but crucial concepts from convex geometry.
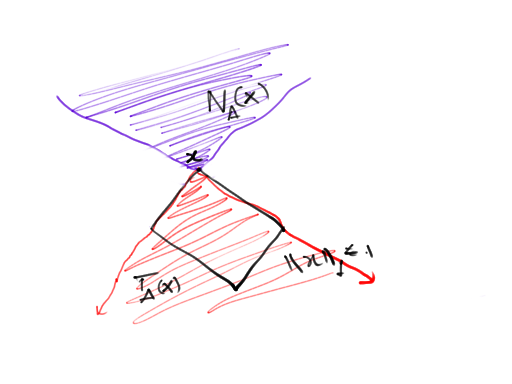
The tangent cone, \(T_{\mathcal{A}}(x)\), gives the directions that decrease \(\|\cdot\|_{\mathcal{A}}\), \[ \begin{align*} T_{\mathcal{A}}(x) &= cone\{ z - x : \|z\|_{\mathcal{A}} \le \|x\|_{\mathcal{A}} \}. \end{align*} \] Similarly, we can define the normal cone, \[ \begin{align*} N_{\mathcal{A}}(x) &= \{ s : \langle s, z-x \rangle \le 0 ~ \forall z : \|z\|_{\mathcal{A}} \le \|x\|_{\mathcal{A}} \}. \end{align*} \] Finally, the polar of a cone \(C^*\) is the set of vectors that are obtuse with respect to all vectors in \(C\). \[ \begin{align*} C^* &= \{ x \in \mathbb{R}^p : \langle x, z \rangle \le 0 ~ \forall z \in C \}. \end{align*} \]
Note that the polar cone of the tangent cone is the normal cone, and vice versa.
Examples. In the \(L_2\) case, i.e. the elements \(\mathcal{A}\) have no structural constraints, the tangent cone is the half space, and the normal cone is the normal of this halfspace. In the \(L_1\) case, the tangent cone is the cone extending from edges of the \(l_1\) ball; the normal cone is the cone bounded by the normals of these two (shown in figure).
Recovering \(x^*\)
We have finally come to the meat of this article; in this section, we will study how the properties of the atomic set, \(\mathcal{A}\), relate to difficulty of recovering \(x^*\).
The first result should illuminate why this approach will work.
(1. Exact Recovery) \(x^*\) is a unique solution to the exact optimization problem iff the tangent cone of the atomic norm at the minimizer and the null-space of the observation operator are transverse, \[ \begin{align} T_{\mathcal{A}}(x^*) \cap\textrm{null}(\Phi) = \{0\}. \label{transverse} \end{align} \]
Recall that the tangent cone \(T_{\mathcal{A}}(x^*)\) gives the descent directions of the objective function (\(\|\cdot\|_{\mathcal{A}}\)) and if \(\delta \in \textrm{null}(\Phi)\), then \(\delta = 0\). Thus, we could move \(\delta\) along these directions and reduce the objective without violating the constraint \(y = \Phi x\).
Now, when we have noisy measurements, we need a stronger condition; that the measurement operator have a “noticeable” projection on the descent directions in \(T_{\mathcal{A}}(x^*)\).
(2. Noisy Recovery) Let \(y = \Phi x^* + \omega, \|\omega\| \le \delta\) be \(n\) noisy measurements and \(\hat x\) be the optimal solution to the noisy optimization problem. If, for all \(z \in T_{\mathcal{A}}(x^*)\), the measurements are bounded below, \[ \begin{align} \|\Phi z\| &\ge \epsilon \|z\| &\forall~ z \in T_{\mathcal{A}}(x^*),\label{bounded-transverse} \end{align} \] then \(\| \hat x - x^* \| \le \frac{2\delta}{\epsilon}\).
As \(\hat x\) minimizes \(\|\cdot\|_{\mathcal{A}}\) in the program, we have that \(\|\hat x\|_{\mathcal{A}} \le \|x^*\|_{\mathcal{A}}\) and thus that \(\hat x - x^* \in T_{\mathcal{A}}(x^*)\). Using the linearity of \(\Phi\) and the triangle inequality, we derive that, \[ \begin{align*} \|\Phi (\hat x - x^*)\|_{\mathcal{A}} &\le \|\Phi \hat x - y \|_{\mathcal{A}} + \|\Phi x^* - y \|_{\mathcal{A}} \\ &\le 2\delta, \end{align*} \] where the first term is upper bounded by \(\delta\) by the optimization program, and the second term is upper bounded by \(\delta\) from assumptions on \(\omega\).
Finally, using the assumption on \(\Phi\), \(\|\Phi (\hat x - x^*)\|_{\mathcal{A}} \ge \epsilon \|\hat x - x^*\|_{\mathcal{A}}\), giving us the finaly result.
\(\Phi\) is a random quantity, so we will have to show that with sufficient samples, the transversity conditions hold with high probability. Note that the assumptions for Lemma 2 subsume those for Lemma 1; it is sufficient for us to estimate a lower bound on \[ \begin{align} \epsilon &= \inf_{z \in T_{A}}(x^*) \frac{ ||\Phi z||_{\mathcal{A}} }{||z||_{\mathcal{A}}}. \label{min-gain} \end{align} \] This quantity will be referred to as the minimum gain of the measurement operator restricted to the cone \(T_{A}(x^*)\).
Aside: Atomic norms are the “best” convex heuristic. One intuition to use the atomic norm is as follows. A basic condition we’d like for heuristic penalty is that it be constant for each atom in the set \(\mathcal{A}\). Consequently, \(a - a'\) should be a descent direction for any \(a, a' \in \mathcal{A}\). Requiring that the penalty be convex implies that the set of descent directions \(\{a - a' \mid a, a' \in \mathcal{A}\}\) should be a cone. This is precisely the tangent cone at \(a \in \mathcal{A}\) with respect to \(\textrm{conv}(\mathcal{A})\).
Gaussian widths and bounding minimum gain
As we noted above, the number of samples required for recovery are determined by minimum gain of \(\Phi\). We will now characterize this quantity in terms of the Gaussian width of the tangent cone, defined below,(Gaussian Width) The Gaussian width of a set \(S \subset \mathbb{R}^p\) is, \(w(S) = \mathbb{E}_{g \sim \mathcal{N}(0, I_n)} [\sup_{z\in S} g^T z ]\).
Of course, because of the linearity of \(\Phi\), the minimum gain is independent of the length of \(z\) so, bounding \(||\Phi z||_{\mathcal{A}}\) on the unit sphere, \(\Omega = T_{\mathcal{A}}(x^*) \cap\mathbb{S}^{p-1}\), is sufficient to bound \(||\Phi z||_{\mathcal{A}}\) on \(T_{\mathcal{A}}\).
Yehoram Gordon (pdf) proved the following key result on when a random subspace escapes a “mesh” in \(\mathbb{R}^n\),(1. Gaussian Width) Let \(\Omega \subset \mathbb{S}^{p-1}\) and \(\Phi : \mathbb{R}^p \to \mathbb{R}^n\) be a random map with i.i.d. standard Gaussian entries. Then, \[ \begin{align*} \mathbb{E}[ \min_{z \in \Omega} \| \Phi z\|_2 ] \ge \lambda_n - w(\Omega), \end{align*} \] where \(\lambda_n\) is the expected length of a \(n\)-dimensional Gaussian vector, \(\mathbb{E}_{g \sim \mathcal{N}(0, I_n)}[ ||g||_2 ]\).
The proof follows from a generalization of the Sudakov-Fernique inequality. It is also useful to note that \(\lambda_k = \sqrt{2} \Gamma(\frac{k+1}{2})/ \Gamma(\frac{k}{2})\), which is tightly bounded, \(\frac{k}{\sqrt{k+1}} \le \lambda_k \le \sqrt{k}\).
Main Theorem: Exponential Convergence to \(x^*\)
We are finally ready to state and prove the main theorem which shows that we need about \(w(\Omega)^2\) samples to exponentially convergence to \(x^*\). Theorem 1 gives us on the minimum gain that holds in expectation. To extend it to the finite sample regime, we’ll exploit the property that \(\Phi \to \min_{z \in \Omega} ||\Phi z||_2\) is Lipschitz (with constant \(1\)) and use the concentration of Gaussian measures to show convergence.
(2. Recovery) Let \(\Phi\) be a random map with rows drawn i.i.d. from \(\mathcal{N}(0, \frac{1}{n} I_n)\) and \(\Omega = T_{\mathcal{A}}(x^*) \cap\mathbb{S}^{p-1}\). Then
Given measurements \(y = \Phi x^*\), then \(x^*\) is the unique solution of the the exact convex program with probability at least \(1 - \exp( -\frac{1}{2}(\lambda_n - w(\Omega))^2 )\), if \(n \ge w(\Omega)^2 + 1\).
- Given measurements \(y = \Phi x^* + \omega, \|\omega\|_2 \le \delta\), then the solution \(\hat x\) of the the noisy convex program satisfies \(\| x^* - \hat x \|_2 \le \frac{2\delta}{\epsilon}\) with probability at least \(1 - \exp( -\frac{1}{2}(\lambda_n - w(\Omega) - \sqrt{n} \epsilon)^2 )\), if \(n \ge \frac{w(\Omega)^2 + 3/2}{(1-\epsilon)^2}\).
This follows directly by using the property that for any Lipschitz function, with constant \(L\), \[ \begin{align*} \mathbb{P}[ f(g) \ge \mathbb{E}[f] - t ] \ge 1 - \exp( - \frac{t^2}{2L^2} ). \end{align*} \]
To see that the map \(\Phi \to \min_{z \in \Omega} \|\Phi z\|_2\) is Lipschitz, observe, \[ \begin{align*} \min_{z \in \Omega} \|\Phi z\|_2 - \min_{z' \in \Omega} \|\Phi' z'\|_2 &\le \|\Phi z'\|_2 - \|\Phi' z'\|_2 \\ &\le \|(\Phi - \Phi')\|_{F} \|z\|_2 \\ &\le \|(\Phi - \Phi')\|_{F}. \end{align*} \]
Thus, we have, \[ \begin{align*} \mathbb{P}[ \min_{z\in \Omega} \|\Phi z\| \ge \epsilon ] &\ge 1 - \exp( -\frac{1}{2}(\lambda_n - w(\Omega) - \sqrt{n} \epsilon )^2 ), \end{align*} \] when \(\lambda_n \ge w(\Omega) - \sqrt{n} \epsilon\). Plugging in \(\epsilon = 0\), we get the first condition as well.
Relationship to Radermacher complexity. In the empirical risk minimization framework, the sample complexity is almost entirely defined by the Radermacher complexity, which is analogous to the Gaussian width, but with expectations taken over binary random variables instead of a Guassian.
Properties of Gaussian Widths
The main theorem shows that the sample complexity is pretty sharply bounded by the Gaussian width \(w(\Omega)\). The Gaussian width of a set is a very well behaved object with many useful properties. We will use these properties in the applications section, but you should feel free to skip the details here for now.
Relationship to Intrinsic Volume
A large number of properties follow from the fact that \(w\) is a valuation, an analogue of a measure. To show this, we’ll use a clever fact that an isotropic Gaussian vector can be separated into two independent parts, length and direction. The direction component integrates over the unit sphere. \[ \begin{align*} w(S) &= \mathbb{E}_g [\sup_{z\in S} g^T z ] \\ &= \underbrace{ \lambda_p }_{\textrm{length}} \int_{\mathbb{S}^{p-1}} \frac{1}{2}( \max_{z \in S} u^T z - \min_{z \in S} u^T z ) \underbrace{\, \mathrm{d}u}_{\textrm{direction}} \\ &= \frac{\lambda_p}{2} b(S), \end{align*} \] where \(b(S)\) is the intrinsic volume of a set (a deterministic property). It turns out (and this is intuitive) that \(\, \mathrm{d}u\) is a Haar measure, giving us the following properties for free.
- \(w(S)\) invariant to translations and unitary transformations.
- Scaling: If \(w(tK) \le t w(K), t > 0\).
- Monotonic: If \(S_1 \subset S_2 \subset \mathbb{R}^p\), \(w(S_1) \le w(S_2)\).
- If \(w( S_1 \cup{} S_2 ) + w( S_1 \cap{} S_2 ) = w(S_1) + w(S_2)\).
- \(w( S ) = w(\textrm{conv}(S))\) (because of the \(\sup\)).
- If \(S = S_1 \oplus S_2\), \(w( S \cap\mathbb{S}^{p-1} ) \le w( S_1 \cap{} \mathbb{S}^{p-1} ) + w( S_2 \cap{} \mathbb{S}^{p-1} )\).
Other Properties
There are a couple of other cool properties that I won’t prove here
- If \(V\) is a vector space, \(w( V \cap\mathbb{S}^{p-1} ) = \sqrt{\dim(V)}\).
- \(w(C \cap\mathbb{S}^{p-1}) \le \mathbb{E}_{g \sim \mathcal{N}(0, I_p)}[ \textrm{dist}(g,C^*) ]\) if \(C\) is a non-empty convex cone in \(\mathbb{R}^p\). The proof follows from convex duality between \(\sup_{z \in C} g^T z\) and \(\textrm{dist}(g,C^*)\).
- A simple corollary; \(w(C \cap\mathbb{S}^{p-1}) + w(C^* \cap\mathbb{S}^{p-1}) \le p\).
- Let \(\mathfrak{N}(S,\epsilon)\) be the \(\epsilon\)-covering number of \(S\). Then, by Dudley’s inequality, \[ \begin{align*} \inf_{\epsilon} c\epsilon \sqrt{\log(\mathfrak{N}(S,\epsilon))} \le w(S) \le 24 \int_{0}^{\infty} \sqrt{\log(\mathfrak{N}(S,\epsilon))} d\epsilon. \end{align*} \]
Applications
We have covered some fairly complex results in this article. To summarize, we showed the convex optimization problem exponentially converges after getting \(O(w(\Omega)^2)\) samples, where \(w(\Omega)\) is the Gaussian width of the tangent cone of the atomic norm \(T_{\mathcal{A}}(x^*)\) at the unit sphere. The Gaussian width has several useful compositional properties (just like the Radermacher complexity). To instantiate the framework, we just need to bound the Gaussian width of the atomic set. In this section, we will do so for two examples, orthogonal matrices and low rank matrices.
Orthogonal Matrices
(3. Orthogonal Recovery) Let \(x^*\) be an \(m \times m\) orthogonal matrix. Then, letting \(\mathcal{A}\) be the set of all orthogonal matrices, \(w(T_{\mathcal{A}}(x^*) \cap\mathbb{S}^{m^2 -1})^2 \le \frac{3 m (m - 1)}{4}\).
Let’s start by defining the atomic norm which should be \(1\) for all elements in \(\mathcal{A}\) and \(\le 1\) for everything in the convex hull \(\textrm{conv}{\mathcal{A}}\). Note that the set of orthogonal matrices is not convex. However, it is not hard to see that every matrix in the convex hull of all \(m \times m\) orthogonal matrices has singular values \(\le 1\); let \(U\) and \(V\) be two orthogonal matrices; \(V = A U\), where \(A\) is also orthogonal. So, \[ \begin{align*} \|\theta U + (1-\theta) V\|_2 &= \|(\theta I + (1-\theta) A) U\|_2 \\ &\le \theta \|I\|_2 + (1-\theta) \|A\|_2 \\ &\le 1, \end{align*} \] where \(||U||_2 = \sigma_1(U)\) is the spectral norm, the largest singular value. We have just shown that the spectral norm is an atomic norm!
Using the property that \(w\) is rotationally invariant, we just need to consider the tangent cone at \(x^* = I\). \[ \begin{align*} T_{\mathcal{A}}(I) &= \textrm{cone}\{ M - I \mid \|M\|_{\mathcal{A}} \le 1 \}. \end{align*} \]
Every matrix \(M\) can be represented as the sum of a symmetric (\(A=A^T\)) and skew-symmetric matrix (\(A=-A^T\)), so we can partion \(T_{\mathcal{A}}(I)\) into these two spaces. The Lie algebra of skew-symmetric matrices is the tangent space of the orthogonal group \(\mathbb{O}(m)\), so we’ll have to consider full subspace. Using the symmetry property, this subset is isomorphic to the \(\binom{m}{2}\) dimensional vector space that defines the entries above (or below) the diagonal.
The remaining component lies in subspace of symmetric matrices, \[ \begin{align*} S &= \textrm{cone}\{ M - I : \|M\|_{\mathcal{A}} \le 1, M~\textrm{symmetric} \} \\ &= \textrm{cone}\{ UDU^T - I : \|D\|_{\mathcal{A}} \le 1, D~\textrm{diagonal} \} \\ &= \textrm{cone}\{ U(D-I)U^T : \|D\|_{\mathcal{A}} \le 1, D~\textrm{diagonal} \} \\ &= -\textrm{PSD}_m , \end{align*} \] where \(\textrm{PSD}_m\) is the set of positive semi-definite \(m \times m\) matrices. The positive semidefinte cone is self-dual (i.e. the polar cone \(\textrm{PSD}_m^* = \textrm{PSD}_m\)) and hence contributes \(\frac{1}{2} \binom{m+1}{2}\).
Putting this together, we have that \(w(\Omega)^2 \le \binom{m}{2} + \frac{1}{2} \binom{m+1}{2}\).
Low-Rank Matrices
(4. Low-rank Recovery) Let \(x^*\) be a \(m_1 \times m_2\) rank-r matrix (\(m_1 \le m_2\)). Then, letting \(\mathcal{A}\) be the set of unit-norm rank-one matrices, \(w(T_{\mathcal{A}}(x^*) \cap\mathbb{S}^{m_1 m_2 -1})^2 \le 3 r (m_1 + m_2 - r)\).
Once again, the set of rank-1 matrices is not convex; the sum of two rank-1 matrices is rarely going to stay rank-1! The spectral norm, \(||M||_* = \sum_{i=1}^{m} \sigma_i(M)\) (i.e. the sum of singular values) is a suitable atomic norm for this set. Firstly, \(\|\cdot\|_*\) is 1 for every element in \(\mathcal{A}\) and is also \(\le 1\) for every element in \(\textrm{conv}\mathcal{A}\). While there may be other choices for \(\|\cdot\|_{\mathcal{A}}\), the spectral norm is a natural choice to minimize the size of the tangent cone, as we’ll shortly see.
Let \(x^* = U\Sigma V^T\), where \(U \in \mathbb{R}^{m_1 \times r}\), \(\Sigma \in \mathbb{R}^{r \times r}\) and \(V \in \mathbb{R}^{m_2 \times r}\). The tangent cone at \(x^*\) is, \[ \begin{align*} T_{\mathcal{A}}(x^*) &= \textrm{cone}\{ M - x^* \mid \|M\|_* \le tr{\Sigma} \}. %\\ % &= \cone \{ U D V^T + U_{\perp} D_{\perp} V_{\perp}^T - U \Sigma V^T \mid \trace(D) + \trace(D_\perp) \le \trace{\Sigma} \}. % &= \cone \{ U_{\perp} D_{\perp} V_{\perp}^T - U (\Sigma - D) V^T \mid \trace(D_\perp) \le \trace(\Sigma - D) \}. \end{align*} \]
To bound the width of this set, we will proceed by bounding the distance to the normal cone. The normal cone is described by the sub-differentials at \(x^*\), \[ \begin{align*} N_{\mathcal{A}}(x^*) &= \textrm{cone}\{UV^T + W : W^T U = 0, WV = 0, \|W\|^*_{\mathcal{A}} \le 1\} \\ &= \{t UV^T + W : W^T U = 0, WV = 0, \|W\|^*_{\mathcal{A}} \le t\}, \end{align*} \] where \(||W||^*_{\mathcal{A}}\) is the dual norm; in our case it’s just the operator norm \(\|\cdot\|_2\). Let \(\Delta\) be directions in the subspaces of \(U\) and \(V\) and \(\Delta^{\perp}\) be directions orthogonal to \(U\) and \(V\).
For any matrix \(G\), a point in normal cone is the projection, \(||P_{\Delta^{\perp}}(G)||_2 UV^T + P_{\Delta^{\perp}}(G)\). Finally, \[ \begin{align*} w(\Omega) &\le \mathbb{E}_{G \sim \mathcal{N}(0, I)}[ \textrm{dist}(G, N_{\mathcal{A}}(x^*)) ] \\ &\le \mathbb{E}[ \|G - Z(G)\|_F^2 ] \\ &= \mathbb{E}[ \|P_{\Delta}(G) + P_{\Delta^\perp}(G) - \|P_{\Delta^{\perp}}(G)\|_2 UV^T - P_{\Delta^{\perp}}(G) \|_F^2 ] \\ &\le \mathbb{E}[ \|P_{\Delta}(G)\|_F^2 ] + \mathbb{E}[ \|P_{\Delta^\perp}(G)\|_2^2 ] \|UV^T\|_F^2 \\ &= \mathbb{E}[ \|P_{\Delta}(G) \|^2 ] + r \mathbb{E}[ \| P_{\Delta^{\perp}}(G)\|_2^2 ]. \end{align*} \] The first term contributes \(r(m_1 + m_2 - r)\) because the dimension of \(P_{\Delta}\) is \(r(m_1 + m_2 - r)\). The second term is calculated by observing that \(P_{\Delta^{\perp}}(G)\) is an isotropic Gaussian \((m_1 - r)\times (m_2 -r)\) matrix. We have good concentration results on the singular values of such random matrices, \[ \begin{align*} \mathbb{P}[ \|P_{\Delta^\perp}(G) \|_2 \ge \sqrt{m_1 - r} + \sqrt{m_2 - r} + s ] &\le \exp(-s^2/2). \end{align*} \] It’s not hard to show from here that \(\mathbb{E}[||P_{\Delta^\perp}(G)||_2^2] \le (\sqrt{m_1 - r} + \sqrt{m_2 - r})^2 + 2\).
Putting this all together, we get our desired result; \[ \begin{align*} w(\Omega) &\le r(m_1 + m_2 - r) + r ((\sqrt{m_1 - r} + \sqrt{m_2 - r})^2 + 2) \\ &\le r(m_1 + m_2 - r) + 2 r(m_1 - r + m_2 - 2r + 1) \\ &\le 3r(m_1 + m_2 - r). \end{align*} \]
Conclusions
I hope through this article I’ve made a case for atomic norms. The framework allows us to reduce the complexity of a recovery problem for arbitrary atomic sets to a Gaussian width computation. Computing the Gaussian widths can still be a hard problem (just like computing the Radermacher complexity), but they provide several useful properties that make these calculations easier. From the few examples I have seen, the Gaussian width calculation requires you to fairly mechanically decompose the tangent cone into spaces that are fairly easy to describe.