How to evaluate your product's AI
April 22, 2025
For the past two decades, benchmarks have been the backbone of AI progress. Capability benchmarks like MMLU, SWE-Bench or HLE have served as proxies for foundation model “IQ.” But they fall short when it comes to evaluating how well AI will perform in your product.1 I’ve spent much of my career building and critiquing evaluations,2 and in this post, I’ll share key lessons on designing an evaluation strategy that reflects real-world product impact.
Lesson 1: User experience is the One True Metric
If your AI doesn’t serve users well, it doesn’t matter how smart it is. That’s why user experience—not benchmark scores—should be the north star of your evaluation strategy. Yes, it’s fuzzy and hard to measure, but ignoring it will cost you.
Case in point: when we worked on Augment’s inline code completions, benchmarks rewarded long, complex code generation. But our biggest leap came from training the model to generate semantically coherent completions—short, intuitive suggestions users could “tab, tab, tab” through without syntax errors. These models actually performed worse on standard benchmarks,3 but felt dramatically better to users. If we’d trusted only the numbers, we’d have missed it.
Lesson 2: You can’t skip steps when climbing the eval staircase
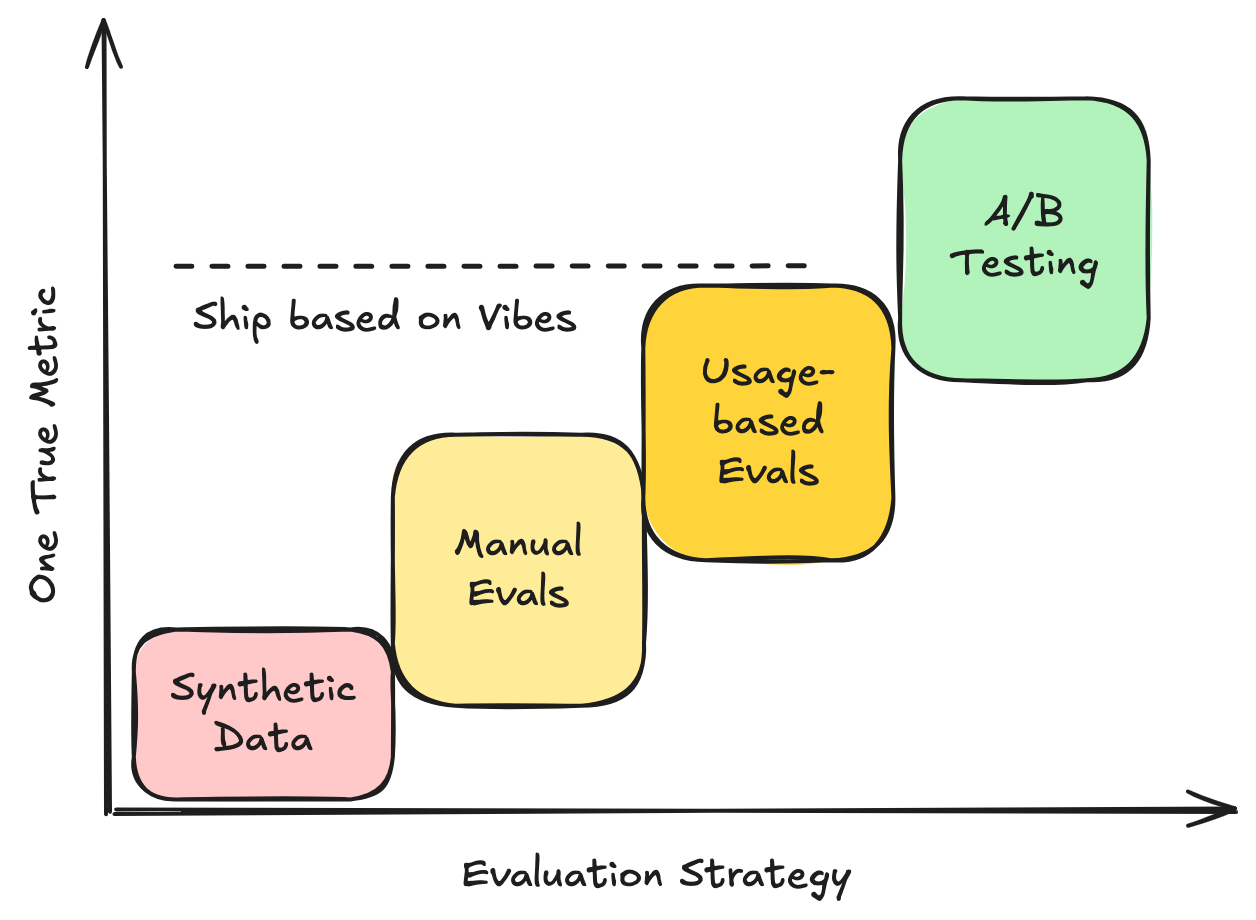
New AI features have to solve the bootstrapping problem: your model isn’t good enough to ship, and without shipping, you can’t gather user data to improve it. You will have to climb the evaluation staircase—one step at a time:
- Synthetic Evals — Their role is to simply get you off the ground, so don’t stay on this step longer than you need to. The two most common options are:
- Adapting Existing Benchmarks — If you’re lucky, there’s a close-enough existing benchmark you can reuse. They’re easy to start with but usually too neat and narrow for real-world usage.4
- Synthetic Validation Data — If not, you might need to simulate data (e.g., with open-source code) to bootstrap training and evaluation. Test on held-out synthetic examples, but tread carefully: overfitting is easy.
- Manual Evals — A curated set of 50–100 examples can go a long way, and is highly underrated. With lightweight tooling, they’re easy to collect and fast to iterate on. Metrics will be noisy—so inspect examples as well. You can often ship a beta at this stage.
- Evals from User Data — After launch, real data trickles in. If users opt in or you hire annotators, you can collect 1k–10k diverse examples and finally get reliable metrics. Just beware: user behavior is shaped by existing models, so it can be biased against new ones. Take scores on new models with a pinch of salt, and don’t ignore vibes.
- A/B Testing — The gold standard. There’s no substitute for statistically sound A/B tests. You often need fewer examples than you think—1k may be enough. Balance across users, tenants, and regions. Use earlier evals to pick contenders, and A/B tests to pick winners.
3. Evals have a burn-in period and a shelf life.
It’s tempting to plug in a new eval and take its numbers at face value, but every new eval needs a burn-in period where you’ll determine its:
- Correlation – Does it agree with notable user experience improvements (and your vibes)?
- Range – What’s a reasonable floor (random baseline) and ceiling (perfect system)?
- Sensitivity – What delta in score is needed to represent real improvements?
Without this trust-building phase, you’ll likely be misled by noise or confounding factors. Plan for multiple iterations of filtering and calibration before trusting an eval.
On the flip side, all evals have a shelf life. As user behavior changes, the eval may stop reflecting the One True Metric. So, revisit regularly.
4. Vibes are a legitimate metric.
Until you’re running A/B tests, most eval metrics are just “numbers” guiding your intuition. In practice, shipping often comes down to vibes: “does this feel better?”
That doesn’t mean evals are useless—they’re critical. But they’re not enough. Despite my academic instincts, I’ve never shipped a model without a vibe check. Here’s how I try to keep those vibes honest:
Test a wide variety of scenarios—not just best cases. Recording yourself using the system helps keep you critical.
Get feedback from users with good taste who catch subtle improvements or regressions.
- Roll out models silently and watch how users react. Users often connect model quality to something changing—even when nothing actually changed!
Final thoughts.
Remember, evaluations aren’t just tools for decision-making—they’re alignment mechanisms. They help your team to move fast in the same direction. But make sure that direction is anchored to what actually matters: the One True Metric—user experience.
Indeed, we’re now seeing the big model players like OpenAI try to “crowdsource” real product evaluations from companies.↩
It so happens that my PhD thesis was all about how to (and not to!) evaluate AI.↩
Actually, the new models initially tanked on the benchmarks because they generated shorter code snippets by design. We were able to mostly fix our eval by chaining completions together. New modelling approaches often have a burn-in period too!↩
For example, SWE-Bench is the benchmark for agentic coding, but real users rarely provide such detailed instructions or well-scoped tasks. Bridging that gap is what made Augment Agent work.↩